Mit KI zum intelligenten Lademanagement
Home | Praxisbeispiele | Mit KI zum intelligenten Lademanagement
Die Elektrifizierung des Verkehrs stellt Betreiber von Ladeinfrastruktur vor neue Herausforderungen. Gemeinsam mit der Firma CUBOS Service GmbH wurden KI-gestützte Ansätze untersucht, um Ladevorgänge effizienter zu steuern. Ziel ist es, Stromangebot, Nutzerverhalten und betriebliche Anforderungen intelligent zu verknüpfen – für ein flexibles, stabiles und kosteneffizientes Lademanagement.
Projektüberblick
Im Projekt mit dem Unternehmen CUBOS Service GmbH wurde untersucht, ob mittels KI-Methoden ein Lademanagementsystem aufgebaut werden kann, das datenbasierte Entscheidungen für das Laden von Elektrofahrzeugen ermöglicht. Auf Basis von rund 20.000 Ladevorgängen wurden mithilfe von Clustering-Algorithmen typische Nutzergruppen identifiziert und durch Prognosemodelle das Ladeverhalten analysiert. Ziel war es, die Standzeit und den Energiebedarf frühzeitig vorherzusagen, um Ladeprioritäten datenbasiert zu steuern. Die KI-Methode soll so die Vermeidung von Lastspitzen unterstützen, die Nutzung erneuerbarer Energien verbessern und Energiekosten senken, was einen praxisnahen Mehrwert für mittelständische Anbieter von Ladeinfrastruktur bietet.
Herausforderung und Zielsetzung
Das Ziel des KI-Anwendungsprojektes liegt darin, zu untersuchen, ob KI-basiert eine Priorisierung beim Laden von Elektrofahrzeugen möglich ist. Ausgangspunkt bildet ein umfangreicher Datensatz mit rund 20.000 anonymisierten Ladevorgängen. Auf dieser Basis soll ein Machine-Learning-Modell erstellt werden, das die Standzeit von Fahrzeugen prognostiziert. Ziel ist es, typische Ladeverhalten zu erkennen und daraus intelligente Steuerungsstrategien abzuleiten. Die Methode soll nicht nur den operativen Aufwand reduzieren, sondern auch durch präzise Vorhersagen zur Vermeidung von Lastspitzen und zur besseren Nutzung erneuerbarer Energien beitragen. Langfristig kann der Ansatz helfen, Energiekosten zu senken, den Eigenverbrauch zu erhöhen und die Netzstabilität durch gezielte Lastverschiebung zu verbessern.
Lösungsweg
So entstand das smarte Lademanagementsystem
Im Folgenden wird der Lösungsweg zur Entwicklung eines KI-gestützten Lademanagementsystems beschrieben. Zuerst erfolgt eine Datenaufbereitung. Aufbauend darauf werden Methoden des überwachten und unüberwachten Lernens genutzt, um den individuellen Ladebedarf zu prognostizieren bzw. die Nutzer in Gruppen einzuteilen. Ziel ist es, aus den historischen Ladevorgängen verwertbare Vorhersagen und Strategien zur datenbasierten Priorisierung abzuleiten.
Datenvorverarbeitung:
Die Datengrundlage besteht aus einer Excel-Datei mit rund 60.000 Ladevorgängen. Erfasst sind Zeitpunkte, Energiemengen, Ladestations-IDs und Fahrzeugkennungen via RFID. Es wird vereinfachend angenommen, dass Fahrzeuge bei ausreichender Standzeit vollständig geladen werden. Zur Plausibilisierung wurde die geladene Energiemenge über Ladeleistung und Ladedauer abgeschätzt. Einschränkungen wie reduzierte Ladeleistung bei Überlast wurden nicht separat berücksichtigt. Für die Modellierung wurden irrelevante Spalten entfernt, Zeitstempel verarbeitet, Einträge vor dem 01.01.2021 ausgeschlossen und fehlende oder fehlerhafte Werte aussortiert. Es blieben nur Ladevorgänge mit plausibler Energiemenge (0–70 kWh), Standzeit (0,5–17,5 h) und Ladeleistung (0–22 kWh/h) erhalten. Das Resultat waren ca. 20.000 gültige Ladevorgänge.
Clustering:
Clustering ist ein Verfahren des unüberwachten Lernens im Bereich des maschinellen Lernens. Ziel ist es, Datenpunkte mit ähnlichen Eigenschaften in Gruppen (sogenannte Cluster) einzuteilen – ohne vorherige Labels oder Klasseninformationen. Die Idee dahinter: Ähnliche Objekte sollen im selben Cluster landen, unterschiedliche in verschiedenen. Clustering wird eingesetzt, um Strukturen, Muster oder Gruppen in großen Datensätzen zu entdecken, etwa bei Kundensegmentierung, Anomalieerkennung oder eben beim Ladeverhalten von Fahrzeugen.
Der K-Means-Algorithmus funktioniert, indem zunächst eine feste Anzahl an Clustern (k) vorgegeben wird. Anschließend werden zufällig k Startpunkte als sogenannte Cluster-Zentren gewählt. Jeder Datenpunkt wird dem nächstgelegenen Zentrum zugewiesen. Danach werden die Zentren neu berechnet, indem der Mittelwert aller zugehörigen Punkte bestimmt wird. Dieser Vorgang der Zuweisung und Neuberechnung wiederholt sich iterativ, bis sich die Zuordnungen nicht mehr verändern oder ein Abbruchkriterium erfüllt ist. K-Means ist rechnerisch effizient und gut interpretierbar, setzt jedoch voraus, dass die Anzahl der Cluster bekannt ist und dass die Daten weitgehend kugelförmige Cluster aufweisen.
Die Bestimmung der Anzahl der Cluster erfolgte hier mit der Ellbogen-Methode. Diese Methode ist ein einfaches und visuell unterstütztes Verfahren zur Bestimmung der optimalen Anzahl von Clustern bei Clustering-Algorithmen wie K-Means. Ziel ist es, eine Balance zwischen Modellkomplexität und Erklärungsqualität zu finden, also eine Anzahl an Clustern zu wählen, die möglichst viel Struktur in den Daten erfasst, ohne zu übersegmentieren. Der Ellbogen für den vorliegenden Fall ist in Bild 1 dargestellt. WCSS (Within-Cluster Sum of Squares) ist die Summe der quadrierten Abstände aller Punkte zu ihrem jeweiligen Cluster-Zentrum und misst die Kompaktheit der Cluster. Bei der Ellbogen-Methode wird WCSS für verschiedene Anzahlen von Clustern berechnet, um den Punkt zu finden, an dem eine weitere Erhöhung der Clusteranzahl nur noch geringe Verbesserungen bringt: den sogenannten Ellbogen. Er stellt einen sinnvollen Kompromiss dar: Die Clusterzahl ist groß genug, um die Daten sinnvoll zu strukturieren, aber klein genug, um Überanpassung zu vermeiden. Es zeigt sich in diesem Fall ein Knick bei k=2, was auf eine zweigeteilte Gruppierung hindeutet.

Bild 1: Ellbogen für die vorliegenden Daten

Tabelle 1: Ergebnisse des Clusterings mit K-Means.

Bild 2: Dichteverteilung der Standzeit für Cluster 0 und Cluster 1
Prognosemodelle:
Im Rahmen der Untersuchung wurde ebenfalls geprüft, inwieweit sich die Standzeit sowie die geladene Energiemenge eines Ladevorgangs bereits zu Beginn prognostizieren lässt. Hierfür wurden verschiedene Verfahren des überwachten maschinellen Lernens eingesetzt, darunter lineare Regression, Regressionsbäume und Random Forest. Die dafür verwendeten Merkmale wie Ankunftszeit, Wochentag, Nutzer- und Ladestations-IDs wurden numerisch kodiert, sodass die Daten in einem ML-tauglichen Format vorlagen.
Die lineare Regression diente als Referenzmodell und zeigte bereits eine solide Prognoseleistung, insbesondere im Hinblick auf die geladene Energie. Die Vorhersage der Standzeit erwies sich über alle Verfahren hinweg als deutlich schwieriger. Während der einfache Regressionsbaum ohne Optimierung nur unzureichende Ergebnisse lieferte, konnte durch Hyperparameter-Tuning (HPT) die Vorhersagequalität verbessert werden. Am besten schnitt das Random-Forest-Modell mit HPT ab. Insgesamt zeigte sich, dass der Energiebedarf besser prognostizierbar ist als die Dauer des Aufenthalts, .
Da die Standzeit trotz Regression nur begrenzt vorhersagbar war, wurde ergänzend ein Klassifikationsansatz verfolgt. Auf Basis zuvor identifizierter Cluster (kurz- und langfristige Ladevorgänge) wurde mithilfe eines RandomForestClassifier versucht, die jeweilige Kategorie vorherzusagen. Auch hier verbesserte HPT die Ergebnisse.
Insgesamt zeigen die Ergebnisse, dass sowohl Regressions- als auch Klassifikationsverfahren einen wertvollen Beitrag zur datenbasierten Prognose im Lademanagement leisten können. Die Genauigkeit ist zwar begrenzt, insbesondere bei der Vorhersage der Standzeit. Dennoch könnten diese Modelle in der Praxis als Entscheidungshilfen für die Priorisierung von Ladevorgängen dienen.
Was?
Datengrundlage
Wie lassen sich Ladezeiten und -mengen von E-Fahrzeugen effizient steuern? Im Rahmen unseres Projekts nutzen wir anonymisierte Daten aus 60.000 Ladevorgängen, um genau das herauszufinden!
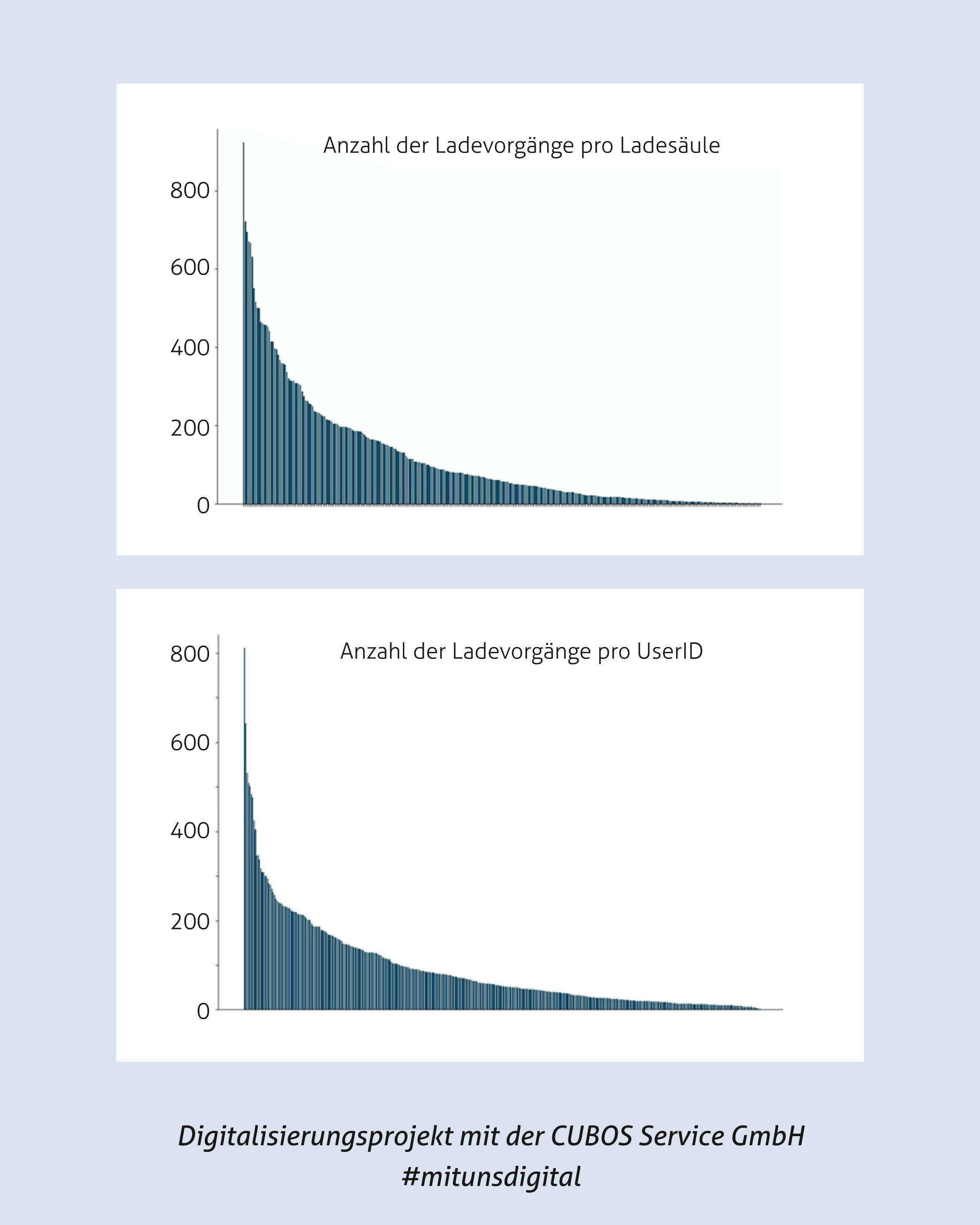
Wie?
Datenvorverarbeitung
Bevor die Daten genutzt werden können, um intelligente Modelle für das Lademanagement zu entwickeln, müssen sie sorgfältig aufbereitet werden.
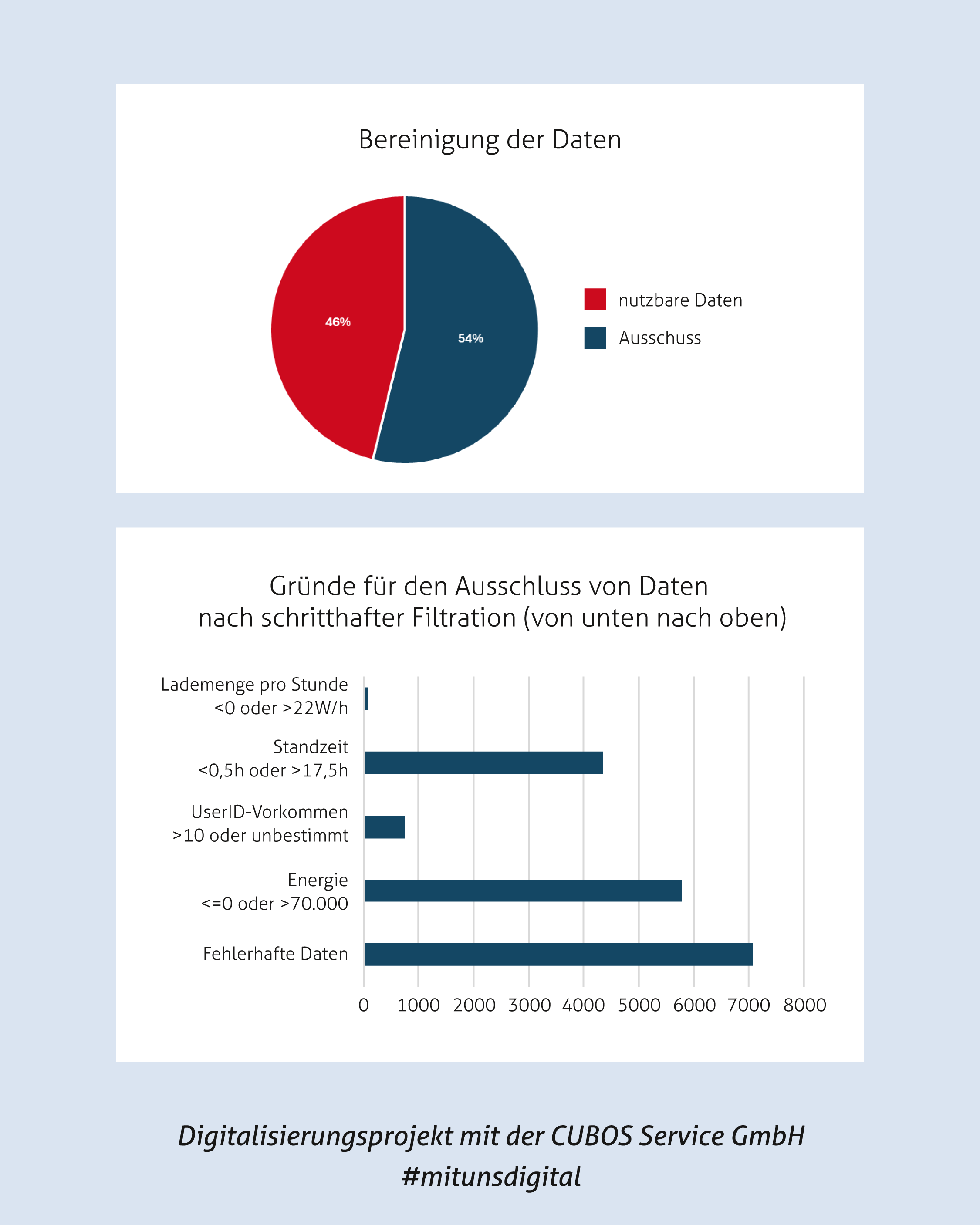
Nutzen für den Mittelstand
Die Ergebnisse zeigen, dass KI-Methoden das Lademanagement in mittelständischen Unternehmen optimieren können und eine praxisnahe Lösung zur effizienteren Nutzung der Ladeinfrastruktur bieten. Durch die datenbasierte Prognose von Standzeiten und Ladeverhalten lassen sich Ladevorgänge besser planen, Lastspitzen vermeiden und Energiekosten senken. Gleichzeitig ermöglicht das System eine intelligentere Nutzung von Eigenstrom – etwa aus Photovoltaik – und steigert so den Eigenverbrauch. Das reduziert nicht nur Betriebskosten, sondern trägt auch zur Netzstabilität und Nachhaltigkeit bei. Für Unternehmen bedeutet das weniger manuellen Aufwand, mehr Planungssicherheit und einen aktiven Beitrag zur Energiewende.
Warum
ist die Datenvorverarbeitung so wichtig?
Das Ziel dieser umfassenden Vorbereitungsprozesse ist es, eine stabile Grundlage zu schaffen, auf der neuronale Netze und Prognosemodelle effizient arbeiten können. Nur mit sauberen, vollständigen und konsistenten Daten können wir eine zukunftsfähige und nachhaltige Steuerung des Lademanagements realisieren.
Identifikation von Ausreißern: Extreme Werte können Analysen verzerren. Durch gezielte Erkennung und Bearbeitung dieser Ausreißer stellen wir sicher, dass die Ergebnisse nicht verfälscht werden.
Überprüfung auf Vollständigkeit: Fehlende Datenpunkte können zu Lücken in den Vorhersagen führen. Wir ergänzen oder entfernen diese, um die Konsistenz der Daten zu gewährleisten.
Datenbereinigung: Um sicherzustellen, dass die Daten von hoher Qualität sind, entfernen wir Rauschen und Inkonsistenzen, die die Modellgenauigkeit beeinträchtigen könnten.
Normierung und Skalierung: Damit die Daten miteinander vergleichbar sind, werden sie standardisiert, was eine genaue Analyse ermöglicht.
Die CUBOS Service GmbH plant und installiert maßgeschneiderte Photovoltaik- und Ladelösungen für Unternehmen, um Energiekosten zu senken und CO₂-Emissionen zu reduzieren. Dabei stehen innovative Ladelösungen im Fokus, die effizientes Laden von E-Fahrzeugen durch smarte Steuerung und Integration in Energiesysteme ermöglichen.
Das könnte Sie auch interessieren


Noch Fragen offen?
Unsere Projekte umfassen einen großen zeitlichen, organisatorischen und thematischen
Umfang. Erfragen Sie die Details einfach beim Projektverantwortlichen. Wir leiten Sie gerne weiter!